Precios basados en el uso según el uso, sin compromisos.50 $ en créditos proporcionados al registrarse, sin necesidad de tarjeta de crédito para empezar hoy mismo. Se aplican límites de tarifa; obtenga límites de tarifa personalizados con compromisos de ingresos. Se aplican costes adicionales para el soporte premium. Póngase en contacto con nosotros para obtener más información.
Empezar - Crédito gratuito1. El uso de la plataforma se mide y se factura por segundos, pero las facturas generadas por nuestro sistema de facturación informan del uso en horas.
2. 2. Cada solicitud de API está sujeta a una facturación mínima de 6 segundos y un incremento de 1 segundo después de eso. Una solicitud de API de 4 segundos se factura por 6 segundos o 0,0012 $ (0,00020 $*6) y una solicitud en tiempo real de 7 segundos se factura 0,00020 $*7.
3. El modelo básico ofrece STT en un mes. El modelo básico ofrece STT en un canal único sin diarización ni redacción de PII. El modelo mejorado ofrece STT para audio de centro de llamadas de dos canales (agente y persona que llama en canales separados) También incluye Diarización (canal mono con varios altavoces) y Redacción PII.
4. STT en tiempo real-Básico y sin Diarización. STT Realtime-Basic y STT Realtime-Enhanced son para streaming de audio sobre Web-socket. Basic es para canal mono sin diarización. Enhanced es para audio de dos canales/estéreo para aplicaciones de call center.
5. Telephony Bot API es la combinación de IVR y Speech-to-Text de Voicegain.
6. MRCP ASR es la ASR en tiempo real de Voicegain. MRCP ASR es el Speech-to-Text/ASR en tiempo real como parte de una Sesión MRCP. Este precio se aplica a toda la duración de la sesión MRCP. No incluye el coste de la grabación del 100% de las sesiones.
7. Se aplican límites de tarifa para el pago por sesión. Ofrecemos límites de tarifa más altos y precios más bajos con compromisos de volumen y plazo. Póngase en contacto con nosotros en sales@voicegain.ai para obtener más información.
Implemente Voicegain en su infraestructura privada. 30 días de prueba gratuita. Licencias disponibles basadas en puertos o en uso. Se aplica una compra mínima de puertos/uso. Además, hay un coste anual de soporte.
Póngase en contacto con nosotros1. Voicegain Edge se refiere a nuestra plataforma desplegada en la infraestructura privada del cliente (Bare-metal en un centro de datos o nube privada). Voicegain se despliega en un clúster Kubernetes. Preferimos GPUs NVIDIA para aplicaciones que requieren alta concurrencia. Las CPU son compatibles con aplicaciones de baja concurrencia. La orquestación del clúster se realiza desde la nube de Voicegain.
2. Costes de infraestructura. El cliente incurrirá en costes de infraestructura y es responsable de la monitorización de Kubernetes. Para Private Cloud, recomendamos Kubernetes gestionado desde el proveedor de cloud. Para Datacenter, por favor contáctenos para opciones de soporte.
3. "Puerto" - para STT Offline - se define como rendimiento. Así, 25 puertos le permitirían transcribir 25 horas de audio sin conexión por hora. Para STT en tiempo real, Puerto es el número de sesiones web-socket concurrentes. Por ejemplo, 25 puertos significa un máximo de 25 sesiones STT simultáneas en tiempo real durante un mes.
4. Licencia por uso. Para las licencias basadas en el uso, cada solicitud está sujeta a una facturación mínima de 6 segundos y un incremento de 1 segundo después de eso. Por ejemplo, una solicitud en tiempo real de 4 segundos se facturará por 6 segundos o 0,0012 $ (0,00020 $*6) y una solicitud en tiempo real de 7 segundos se facturará por 7 segundos.
5. Voicegain ofrece descuentos por volumen. Voicegain ofrece descuentos por volumen y plazos. Póngase en contacto con nosotros en sales@voicegain.ai para recibir precios personalizados.

Puedes transmitir audio para la API de transcripción de Voicegain desde cualquier ordenador, pero a veces es útil tener un dispositivo barato dedicado sólo para esta tarea. A continuación relatamos la experiencia de uno de nuestros clientes en el uso de una Raspbery Pi para transmitir audio para la transcripción en tiempo real. Sustituyó a un Mac Mini que se utilizó inicialmente para ese fin. El uso de Pi tenía dos ventajas: a) obviamente, el coste, y b) es menos probable que el Mac Mini sea "secuestrado" para otros fines.
Voicegain Audio Streaming Daemon requiere muy poco en cuanto a recursos informáticos, por lo que incluso en una Raspberry Pi Zero es suficiente; sin embargo, recomendamos usar Raspberry Pi 3 B+ principalmente porque tiene a bordo un puerto Ethernet cableado de 1Gbps. Las conexiones WiFi son más propensas a tener problemas con el streaming utilizando el protocolo UDP.
Aquí hay una lista de todo el hardware utilizado en el proyecto (con precios de amazon (a julio de 2019)):
Todos los componentes sumaron un total de 101,97 dólares. La razón por la que se incluyeron un mini monitor y un mini teclado es que hacen más cómodo controlar el dispositivo mientras está en el rack de audio. Por ejemplo, el mezclador de audio alsa se puede ajustar fácilmente de esta manera, mientras que al mismo tiempo se controla el nivel del audio a través de los auriculares.

Raspberry PI ejecutando AudioDaemon
El dispositivo está ejecutando Raspbian estándar que se puede instalar fácilmente desde una imagen utilizando, por ejemplo, balenaEtcher. Después de la instalación base, se necesitaba lo siguiente para poner las cosas en marcha:
Estas son algunas de las lecciones aprendidas con esta configuración en los últimos 6 meses:

Puedes encontrar el código completo (menos la lógica RASA - tendrás que proporcionar la tuya propia) en nuestro repositorio github.
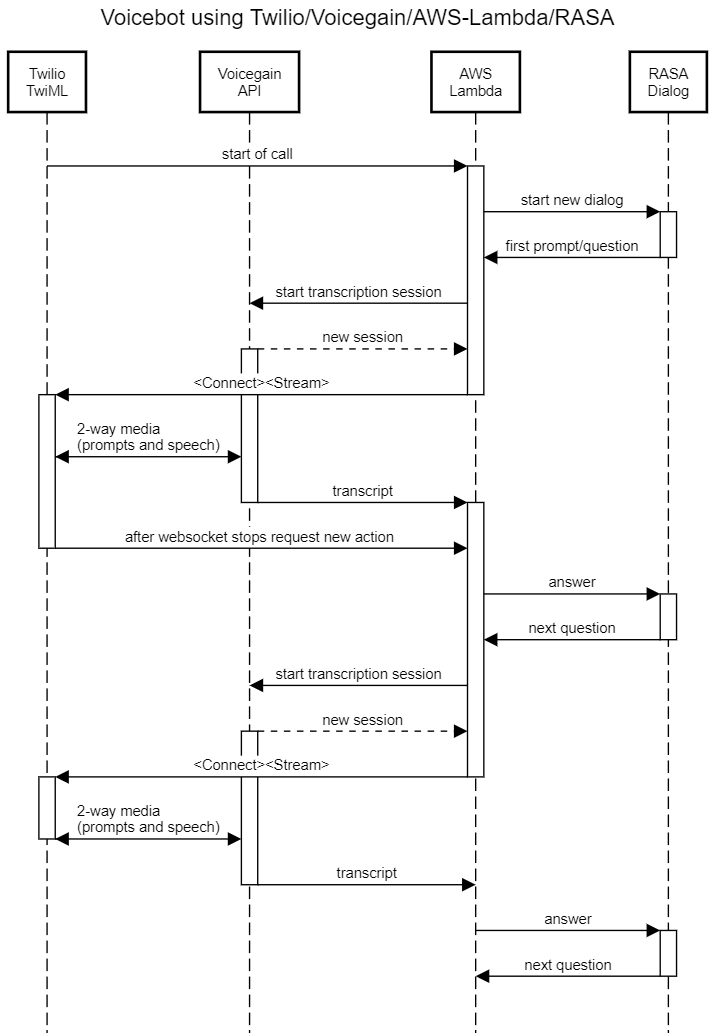
La configuración permite llamar a un número de teléfono y luego interactuar con un Voicebot que utiliza RASA como motor lógico de diálogo.
Actualización de noviembre de 2021: No recomendamos S3 y AWS Lambda para una configuración de producción. Una revisión más actualizada de varias opciones para construir un Voice Bot se describe aquí. Debería considerar sustituir la funcionalidad de S3 y AWS Lambda por un servidor web capaz de mantener el estado, como Node.js o Python Flask.
A continuación se presenta el diagrama secuencial. Básicamente, la secuencia de operaciones es la siguiente:
"Elegimos Voicegain porque es preciso, asequible y fácil de usar. Desplegamos toda la plataforma en nuestro centro de datos en menos de 30 minutos".
"Seleccionamos Voicegain para Sutherland CX360, nuestra oferta AI/ML SaaS para evaluar todas las interacciones CX de Sutherland. Buscábamos una oferta ASR/STT precisa que cumpliera la normativa PCI para nuestros clientes empresariales y la encontramos en Voicegain...".
"Voicegain es increíble. Tienen un gran ASR y una arquitectura moderna. Pero lo que realmente valoramos es su asistencia rápida y oportuna. Utilizamos sus API MRCP ASR y STT y funcionan de maravilla".
¿Le interesa personalizar el ASR o implantar Voicegain en su infraestructura?
Voicegain ayuda a los desarrolladores a crear increíbles aplicaciones de voz proporcionándoles la plataforma de voz a texto más precisa, asequible y accesible.


'%3e%3cg id='Final-Copy-2_2_' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st0' d='M7.4,12.8h6.8l3.1-11.6H7.4C4.2,1.2,1.6,3.8,1.6,7S4.2,12.8,7.4,12.8z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg id='final---dec.11-2020'%3e%3cg id='_x30_208-our-toggle' transform='translate(-1275.000000, -200.000000)'%3e%3cg id='Final-Copy-2' transform='translate(1275.000000, 200.000000)'%3e%3cpath class='st1' d='M22.6,0H7.4c-3.9,0-7,3.1-7,7s3.1,7,7,7h15.2c3.9,0,7-3.1,7-7S26.4,0,22.6,0z M1.6,7c0-3.2,2.6-5.8,5.8-5.8 h9.9l-3.1,11.6H7.4C4.2,12.8,1.6,10.2,1.6,7z'/%3e%3cpath id='x' class='st2' d='M24.6,4c0.2,0.2,0.2,0.6,0,0.8l0,0L22.5,7l2.2,2.2c0.2,0.2,0.2,0.6,0,0.8c-0.2,0.2-0.6,0.2-0.8,0 l0,0l-2.2-2.2L19.5,10c-0.2,0.2-0.6,0.2-0.8,0c-0.2-0.2-0.2-0.6,0-0.8l0,0L20.8,7l-2.2-2.2c-0.2-0.2-0.2-0.6,0-0.8 c0.2-0.2,0.6-0.2,0.8,0l0,0l2.2,2.2L23.8,4C24,3.8,24.4,3.8,24.6,4z'/%3e%3cpath id='y' class='st3' d='M12.7,4.1c0.2,0.2,0.3,0.6,0.1,0.8l0,0L8.6,9.8C8.5,9.9,8.4,10,8.3,10c-0.2,0.1-0.5,0.1-0.7-0.1l0,0 L5.4,7.7c-0.2-0.2-0.2-0.6,0-0.8c0.2-0.2,0.6-0.2,0.8,0l0,0L8,8.6l3.8-4.5C12,3.9,12.4,3.9,12.7,4.1z'/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e) Sus opciones de privacidad
Sus opciones de privacidad